
TCMalloc also reduces lock contention for multi-threaded programs. For small objects, there is virtually zero contention. For large objects, TCMalloc tries to use fine grained and efficient spinlocks. ptmalloc2 also reduces lock contention by using per-thread arenas but there is a big problem with ptmalloc2's use of per-thread arenas. In ptmalloc2 memory can never move from one arena to another. This can lead to huge amounts of wasted space. For example, in one Google application, the first phase would allocate approximately 300MB of memory for its data structures. When the first phase finished, a second phase would be started in the same address space. If this second phase was assigned a different arena than the one used by the first phase, this phase would not reuse any of the memory left after the first phase and would add another 300MB to the address space. Similar memory blowup problems were also noticed in other applications.
Another benefit of TCMalloc is space-efficient representation of small
objects. For example, N 8-byte objects can be allocated while using
space approximately 8N * 1.01 bytes. I.e., a one-percent
space overhead. ptmalloc2 uses a four-byte header for each object and
(I think) rounds up the size to a multiple of 8 bytes and ends up
using 16N bytes.
To use TCmalloc, just link tcmalloc into your application via the "-ltcmalloc" linker flag.
You can use tcmalloc in applications you didn't compile yourself, by using LD_PRELOAD:
$ LD_PRELOAD="/usr/lib/libtcmalloc.so"
LD_PRELOAD is tricky, and we don't necessarily recommend this mode of usage.
TCMalloc includes a heap checker and heap profiler as well.
If you'd rather link in a version of TCMalloc that does not include
the heap profiler and checker (perhaps to reduce binary size for a
static binary), you can link in libtcmalloc_minimal
instead.
TCMalloc treates objects with size <= 32K ("small" objects) differently from larger objects. Large objects are allocated directly from the central heap using a page-level allocator (a page is a 4K aligned region of memory). I.e., a large object is always page-aligned and occupies an integral number of pages.
A run of pages can be carved up into a sequence of small objects, each equally sized. For example a run of one page (4K) can be carved up into 32 objects of size 128 bytes each.
A thread cache contains a singly linked list of free objects per size-class.
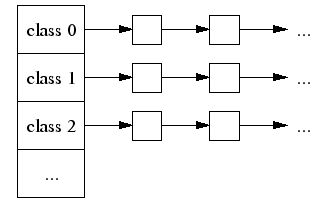
If the free list is empty: (1) We fetch a bunch of objects from a central free list for this size-class (the central free list is shared by all threads). (2) Place them in the thread-local free list. (3) Return one of the newly fetched objects to the applications.
If the central free list is also empty: (1) We allocate a run of pages from the central page allocator. (2) Split the run into a set of objects of this size-class. (3) Place the new objects on the central free list. (4) As before, move some of these objects to the thread-local free list.
i < 256, the
kth entry is a free list of runs that consist of
k pages. The 256th entry is a free list of
runs that have length >= 256 pages:

An allocation for k pages is satisfied by looking in the
kth free list. If that free list is empty, we look in
the next free list, and so forth. Eventually, we look in the last
free list if necessary. If that fails, we fetch memory from the
system (using sbrk, mmap, or by mapping in portions of /dev/mem).
If an allocation for k pages is satisfied by a run
of pages of length > k, the remainder of the
run is re-inserted back into the appropriate free list in the
page heap.
Span object. A span
can either be allocated, or free. If free, the span
is one of the entries in a page heap linked-list. If allocated, it is
either a large object that has been handed off to the application, or
a run of pages that have been split up into a sequence of small
objects. If split into small objects, the size-class of the objects
is recorded in the span.
A central array indexed by page number can be used to find the span to which a page belongs. For example, span a below occupies 2 pages, span b occupies 1 page, span c occupies 5 pages and span d occupies 3 pages.
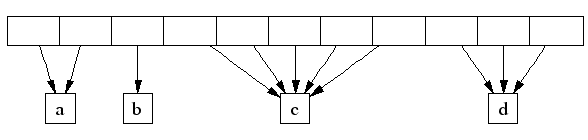
If the object is large, the span tells us the range of pages covered
by the object. Suppose this range is [p,q]. We also
lookup the spans for pages p-1 and q+1. If
either of these neighboring spans are free, we coalesce them with the
[p,q] span. The resulting span is inserted into the
appropriate free list in the page heap.
An object is allocated from a central free list by removing the first entry from the linked list of some span. (If all spans have empty linked lists, a suitably sized span is first allocated from the central page heap.)
An object is returned to a central free list by adding it to the linked list of its containing span. If the linked list length now equals the total number of small objects in the span, this span is now completely free and is returned to the page heap.
We walk over all free lists in the cache and move some number of objects from the free list to the corresponding central list.
The number of objects to be moved from a free list is determined using
a per-list low-water-mark L. L records the
minimum length of the list since the last garbage collection. Note
that we could have shortened the list by L objects at the
last garbage collection without requiring any extra accesses to the
central list. We use this past history as a predictor of future
accesses and move L/2 objects from the thread cache free
list to the corresponding central free list. This algorithm has the
nice property that if a thread stops using a particular size, all
objects of that size will quickly move from the thread cache to the
central free list where they can be used by other threads.
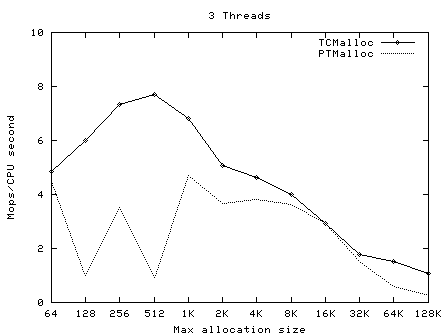
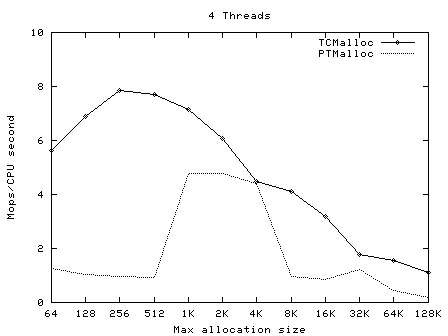
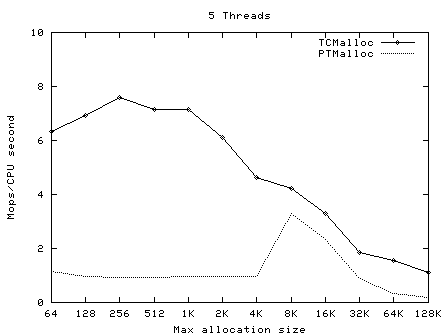
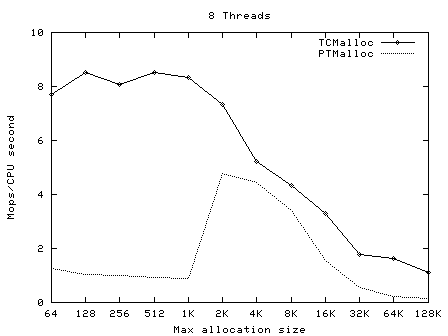
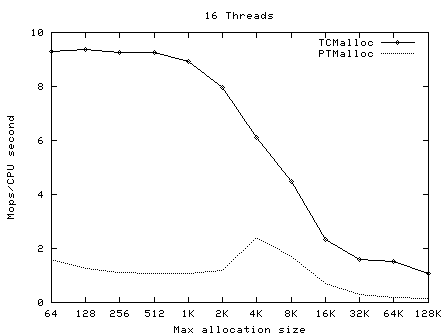
t-test1 (included in google-perftools/tests/tcmalloc, and compiled as ptmalloc_unittest1) was run with a varying numbers of threads (1-20) and maximum allocation sizes (64 bytes - 32Kbytes). These tests were run on a 2.4GHz dual Xeon system with hyper-threading enabled, using Linux glibc-2.3.2 from RedHat 9, with one million operations per thread in each test. In each case, the test was run once normally, and once with LD_PRELOAD=libtcmalloc.so.
The graphs below show the performance of TCMalloc vs PTMalloc2 for several different metrics. Firstly, total operations (millions) per elapsed second vs max allocation size, for varying numbers of threads. The raw data used to generate these graphs (the output of the "time" utility) is available in t-test1.times.txt.
 |
 |
 |
 |
 |
 |
 |
 |
 |
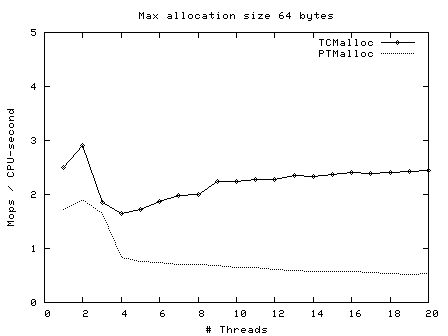
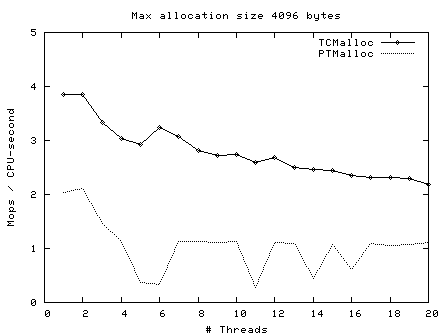
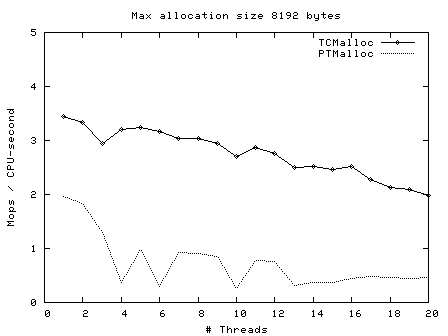
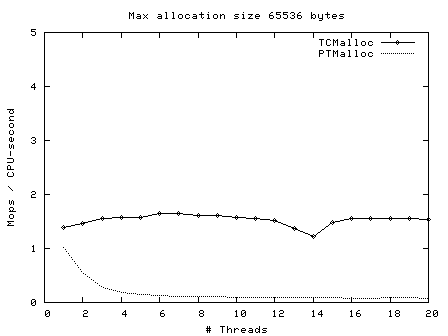
Next, operations (millions) per second of CPU time vs number of threads, for max allocation size 64 bytes - 128 Kbytes.
 |
 |
 |
 |
 |
 |
 |
 |
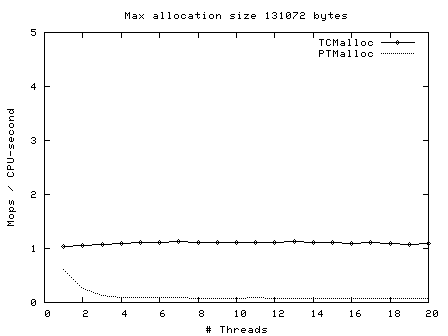 |
Here we see again that TCMalloc is both more consistent and more efficient than PTMalloc2. For max allocation sizes <32K, TCMalloc typically achieves ~2-2.5 million ops per second of CPU time with a large number of threads, whereas PTMalloc achieves generally 0.5-1 million ops per second of CPU time, with a lot of cases achieving much less than this figure. Above 32K max allocation size, TCMalloc drops to 1-1.5 million ops per second of CPU time, and PTMalloc drops almost to zero for large numbers of threads (i.e. with PTMalloc, lots of CPU time is being burned spinning waiting for locks in the heavily multi-threaded case).
For some systems, TCMalloc may not work correctly on with applications that aren't linked against libpthread.so (or the equivalent on your OS). It should work on Linux using glibc 2.3, but other OS/libc combinations have not been tested.
TCMalloc may be somewhat more memory hungry than other mallocs, though it tends not to have the huge blowups that can happen with other mallocs. In particular, at startup TCMalloc allocates approximately 6 MB of memory. It would be easy to roll a specialized version that trades a little bit of speed for more space efficiency.
TCMalloc currently does not return any memory to the system.
Don't try to load TCMalloc into a running binary (e.g., using JNI in Java programs). The binary will have allocated some objects using the system malloc, and may try to pass them to TCMalloc for deallocation. TCMalloc will not be able to handle such objects.